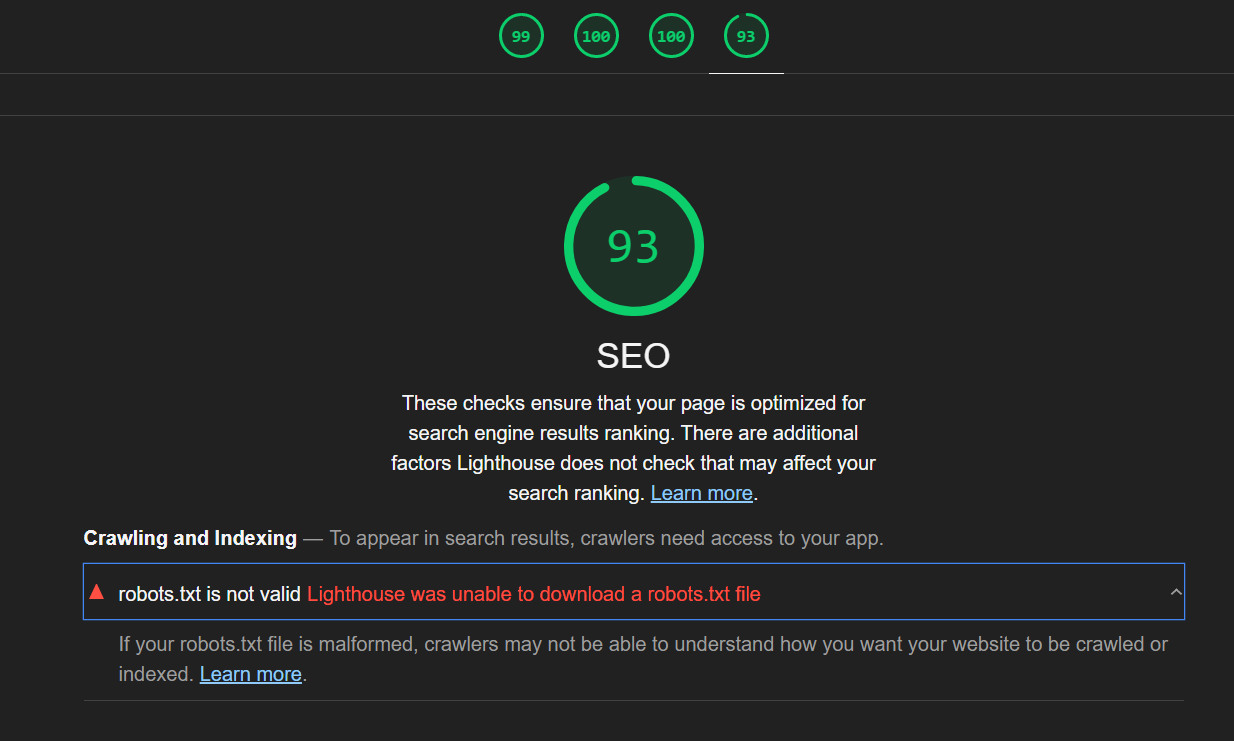
Lỗi do chính sách bảo mật nội dung của trình duyệt
Như bạn đã biết, tệp robots.txt cho phép bạn thực thi các quy tắc thu thập dữ liệu để các bots tìm kiếm nhận diện các dữ liệu được phép thu thập hoặc không được thu thập.Link của tệp này sẽ có đường dẫn như sau https://domain.com/robots.txt , khi bạn truy cập link này thì vẫn load ra nội dung của file robots.txt bình thường.Lighthouse cố gắng tìm và tải tập tin robots.txt thông qua việc thực thi một tập lệnh fetch đến file tĩnh . Dưới đây là đoạn mã mà nó sử dụng để thực hiện việc này (được đặt trong thư mục lighthouse-core):const response = await fetch(new URL(‘/robots.txt’, location.href).href);Tất nhiên là bạn sẽ gặp cảnh báo lỗi khi thực hiện lệnh fetch trên một website, vì nó được quy định trong các chính sách bảo mật nội dung của trình duyệt.Điều này cũng một phần là do các plugin SEO như Rank Math SEO, Yoast SEO,… không tạo ra các tệp robots.txt tĩnh, nhằm linh hoạt trong việc ghi thêm các quy tắc SEO vào tệp này.Lỗi do CDN
Một số trường hợp khác khi bạn sử dụng các CDN như Cloudflare cũng ghi nhận tình trạng tương tự.Khi bạn liên kết tên miền vào Cloudflare, Cloudflare sẽ thêm endpoint /cdn-cgi/ vào tên miền của bạn, nó có dạng như sau www.domain.com/cdn-cgi/Một vài ví dụ về tác dụng của endpoint này như:- Xác định trung tâm dữ liệu Cloudflare phục vụ yêu cầu , điều này giúp ích cho việc khắc phục sự cố (
https://<YOUR_DOMAIN>/cdn-cgi/trace). - Phát hiện JavaScript được sử dụng bởi các sản phẩm bot của Cloudflare (
example.com/cdn-cgi/challenge-platform/) - Chuyển đổi hình ảnh trong các URL mới mà bạn sẽ sử dụng cho hình ảnh (
example.com/cdn-cgi/image/) - Che giấu địa chỉ email được sử dụng để ẩn địa chỉ email khỏi các bot độc hại (
example.com/cdn-cgi/l/email-protection) - Phân tích trang web cho một trang web được ủy quyền thông qua Cloudflare (
example.com/cdn-cgi/rum). Điểm cuối này trả về204mã trạng thái HTTP.

Do phân quyền tệp robots.txt
Đây cũng là một lỗi phổ biến, vì khi file robots.txt bị phân quyền sai, dẫn tới bạn không thể đọc và tải xuống file robots.txt được.Một tệp tin thông thường sẽ có mã phân quyền là 644, đối với thư mục sẽ là 755.Cách xử lý lỗi
Tạo lại tệp robots.txt tĩnh trên source code web
Đây là cách đơn giản và nhanh chóng nhất, bạn chỉ cần truy cập link https://domain.com/robots.txt, sau đó nhấn phím ctrl+s để tải file robots.txt về máy tính.Sau đó truy cập và upload load nó vào thư mục gốc của web trên Hosting/Server.Kết quả trông sẽ như ảnh dưới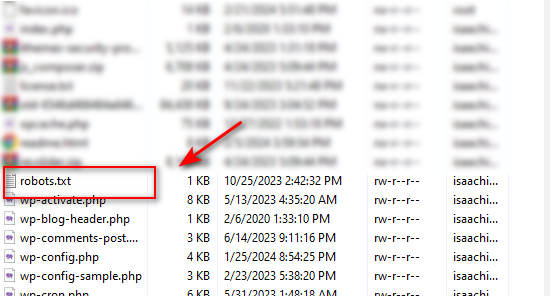
Disallow CDN trong robots.txt
Với cách này, bạn sẽ tiến hành sửa lại file robots.txt và chèn quy tắc sauDisallow: /cdn-cgi/Kết quả sẽ trông giống như ảnh sau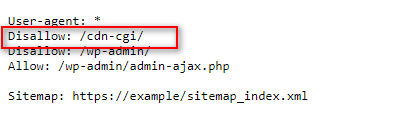
Mở quyền fetch cho tệp robots.txt trên Hosting/Server
Có nhiều cách để mở quyền fetch cho một tệp, nếu Webserver của bạn là Litespeed, Apache thì bạn có thể chèn quy tác sau vào file .htaccessHeader set Content-Security-Policy "connect-src *;"Quy tác này sẽ cho phép việc thực thi lệnh fetch từ mọi miền bên ngoài vào website. Hãy cẩn trọng khi áp dụng cách này vì nó có thể bị lợi dụng để khai thác dữ liệu hoặc tấn công vào website của bạn.Thiết lập lại phân quyền cho robots.txt
Nếu file robots.txt của bạn phân quyền sai, hãy truy cập vào bảng điều khiển của bạn và phân lại quyền của file sang 644.Dưới đây là ví dụ khi tôi sửa đổi phân quyền trên Bảng điều khiển Cpanel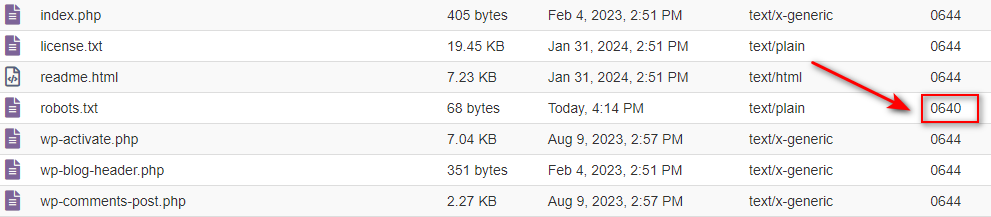
Tổng kết
Việc sửa lỗi “robots.txt is not valid” trên Google Pagespeed Insight không quá quan trọng, miễn là bạn đảm bảo được khi truy cập link https://domain.com/robots.txt vẫn load được ra nội dung là được.Nguồn:tại đây5/5 - (1 vote)